 My Corner of the Web
My Corner of the Web
In 2002, while earning my Master's degree in computer science, I created an XML database called "xSQL" that created an XML backing store with an SQL front end. After completing my new book, "Information as Product", I realized that this backing store (with some improvements) would be ideal to store metadata. The reason for this is so that you could immediately expose metadata on the web (for example via a simple XSLT script that transformed the XML to HTML tables) and thus quickly enable mutltiple views of your metadata - an "SQL" view for applications, an XML view for SOA services and an HTML view for web transparency. This is a prime example of "Information MVC" as described in the book.
Below, I have the initial design document for the system which also expresses the current state of the software. In the downloads section I have placed a "developers preview" that will enable you to run this as a command line tool. The purpose of this preview is simply to guage the interest of other developers in working on this with me via an open source project. I will also be working on a "User Preview" that will have a graphical user interface. If you are interested, please email me via the Contact link (put the tag [IAP MDB Developer] in your subject so I do not delete your email as spam.
Once I get sufficient interest to start an open source project, I will post the source code. The long term roadmap for this project would be as one potential backing store (possibly amid others) for a metadata catalog.
Software Design Document for the IAP Metadata Database (IAP MDB)
(formerly called "xSQL")
Initial Design: 6/17/2002
Michael C. Daconta
Initial code developed for CISC-660 Course Project Option III
Table of Contents
6.1 Implementation Lessons Learned. 13
Introduction
The purpose of this document is to describe, in detail, the high-level and detailed system design of the “Information As Product”[1] (IAP) Metadata Database (MDB). The scope of this document is only the concepts and software that implement the requirements specified in the requirements document (referenced in section 1.1) and not the design of any supporting software (like the Java CUP parser). The intended audience for this document is senior object-oriented developers since basic object oriented programming (OOP) principles will not be covered.
References
The following documents were used in developing this design:
1. xSQL mini-dbms Software Requirements Specification (SRS) dated June 16, 2002 by Michael C. Daconta.
2. CISC 660 Project Option III description by Dr. Junping Sun.
3. Fundamentals of Database Systems, 3rd Ed., by Elmasri and Navathe, © 2000.
4. Design Patterns, by Gamma, Helm, Johnson & Vlissides, © 1995.
System Overview
The general goal of the system is a learning project to implement the components of a database management system. The general implementation strategy was to attempt to combine the popular XML syntax with a relational database management system. The approach was to use XML as the backing store upon which to implement an SQL front-end. The reason for this approach was to open up relational data to the wide array of XML processing tools available like the eXtensible Stylesheet Language Transformations (XSLT) processors. Figure 1 depicts the initial proposal for the project presented on 5/25/02.
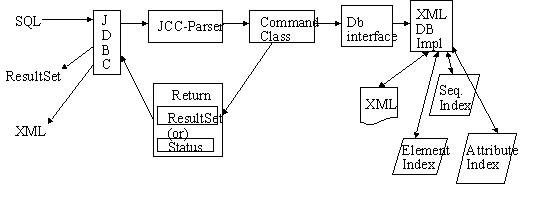
Figure 1. Proposal for CISC-660 Course Project
While the proposal in Figure 1 conveys the general strategy of an XML backing store, it was overly ambitious given the approximately three-week (part-time) implementation period. Also, the JDBC API was superfluous to the assignment requirements and unnecessary since the user interface requirements called for a simple interactive (not programmatic) interface. In that same vein, the element and attribute indexes are more applicable to an XPath or XQuery interface than the required SQL interface and were therefore not implemented. Lastly, the java CUP parser generator was substituted for JavaCC because I was more familiar with Java CUP as it was used in CISC 630.
Constraints and Goals
The constraints on the design of the system came from the requirements document and the CISC 660 project description. Chief among these constraints was adherence to the valid SQL syntax. This guided the design choice of using a parser generator instead of a hand-crafted parser. The general strategy of an XML backing store imposed the XML syntax as a constraint. The choice of the Java platform constrained the design to the Java libraries. One final self-imposed constraint was for the command line interpreter to execute similar to the Oracle SQL*Plus program that we used throughout the course.
The goals for the system were to allow results to be returned in either text or XML format without a significant performance penalty; to implement the required functionality and to explore the indexing and retrieval of records in “raw” XML format.
Architecture Strategies
The design was guided by seven architectural strategies:
1. CUP Parser Generator / JLex for parsing SQL. This necessitated formal grammars but provided greater parsing accuracy. This was also hinted at in the course project description via the suggestion of a book on “Lex and Yacc” for reference material.
2. Translation of SQL syntax into an abstract syntax. Similar to the building of a compiler, an intermediate class hierarchy of objects allows a separation of intent from syntax. These classes all reside in the “absyn” package detailed in section 5.3.
3. Command pattern. Encapsulating the SQL commands in objects that implement a common Command interface, allowed the command interpreter to be unaware of the commands it was executing. This will significantly aid the reuse of the classes for another user interface, specifically a graphical user interface.
4. A text/index based XML backing store. There are three common ways to store XML: a new data type in a traditional dbms; raw text; and as a serialized Document Object Model (DOM). Since this project is implementing a dbms, the first option is not a candidate. Serializing a DOM has some advantages and is a common method for some of the leading native XML databases like Tamino by Software AG and eXcelon; however, there are two drawbacks to the DOM approach: most XML parsers generate a DOM by parsing the entire document which would be memory intensive and secondly, a DOM (like a traditional database) still requires a transformation from objects to XML when sending results sets in XML syntax. Therefore, in an attempt to optimize XML retrievals of whole records, the storage choice for a table was a combination of a record-based XML document structure (no multi-level hierarchies) stored as raw text and a binary index of the record boundaries was chosen as the strategy. Listing 1 is a sample DEPARTMENT table in XML syntax containing three tuples.
Listing 1. Sample Relational Table in XML syntax.
<?xml version="1.0"?>
<table>
<row>
<dname>Headquarters</dname>
<dnumber>1</dnumber>
<mgrssn>888665555</mgrssn>
<mgrstartdate>19-JUN-71</mgrstartdate>
</row>
<row>
<dname>Administration</dname>
<dnumber>4</dnumber>
<mgrssn>987654321</mgrssn>
<mgrstartdate>01-JAN-85</mgrstartdate>
</row>
<row>
<dname>Research</dname>
<dnumber>5</dnumber>
<mgrssn>333445555</mgrssn>
<mgrstartdate>22-MAY-78</mgrstartdate>
</row>
</table>
5. The database catalog implemented as a table. Since the database schema contains record data where each table definition is a record, it can also be represented as an XML table. This same approach is discussed on page 574 of [3]. Since the format of the catalog table is static (not based on column names), the XML schema definition can be fixed. Listing 2 is the XML schema definition for the database catolog. While the current dbms does not implement schema validation, that could be easily added to a future release.
Listing 2. Schema for Database catalog.
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema targetNamespace="http://scis.nova.edu/cisc660/xdb" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns="http://scis.nova.edu/cisc660/xdb" elementFormDefault="qualified" attributeFormDefault="unqualified">
<xsd:element name="dbschema">
<xsd:annotation>
<xsd:documentation>recordElement="relation"</xsd:documentation>
</xsd:annotation>
<xsd:complexType>
<xsd:sequence>
<xsd:element name="relation" type="relationType"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:complexType name="relationType">
<xsd:sequence>
<xsd:element name="field" type="fieldType" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
<xsd:attribute name="name" type="xsd:string"/>
<xsd:attribute name="created" type="xsd:date"/>
<xsd:attribute name="updated" type="xsd:date"/>
<xsd:attribute name="numFields" type="xsd:int"/>
</xsd:complexType>
<xsd:complexType name="fieldType">
<xsd:attribute name="name" type="xsd:string"/>
<xsd:attribute name="type" type="xsd:string"/>
<xsd:attribute name="size" type="xsd:int"/>
<xsd:attribute name="primaryKey" type="xsd:string"/>
</xsd:complexType>
</xsd:schema>
Listing 3 is an XML instance which conforms to the schema in listing 2. This version of the database catalog contains a description of three relations (CONTACT, DEPARMENT and EMPLOYEE).
Listing 3. XML Instance of the database catalog
<?xml version="1.0"?>
<dbschema>
<relation name="CONTACT" numFields="3">
<field name="NAME" type="0" size="16" primaryKey="false"/>
<field name="EMAIL" type="0" size="20" primaryKey="false"/>
<field name="ADDRESS" type="0" size="30" primaryKey="false"/>
</relation>
<relation name="DEPARTMENT" numFields="4">
<field name="dname" type="0" size="15" primaryKey="false"/>
<field name="dnumber" type="0" size="8" primaryKey="true"/>
<field name="mgrssn" type="0" size="9" primaryKey="false"/>
<field name="mgrstartdate" type="0" size="12" primaryKey="false"/>
</relation>
<relation name="EMPLOYEE" numFields="7">
<field name="name" type="0" size="20" primaryKey="false"/>
<field name="ssn" type="0" size="9" primaryKey="true"/>
<field name="bdate" type="0" size="12" primaryKey="false"/>
<field name="sex" type="0" size="3" primaryKey="false"/>
<field name="salary" type="1" size="6" primaryKey="false"/>
<field name="superssn" type="0" size="9" primaryKey="false"/>
<field name="dno" type="0" size="8" primaryKey="false"/>
</relation>
</dbschema>
6. Record based index files with fixed sized indexes. Since all comparisons are record based, it is important to be able to extract a single record (called a “row” element in listing 1). To accomplish this, a table managed by the DBMS consists of two files, a text file and at least one binary index file (sequential listing of records). The class that accomplishes this is called DbFile and discussed in Section 5.4.
7. Marked deletes instead of physical deletes. As discussed on page 136 of [3], a deletion marker can be added to the index instead of an actual removal of the record. This makes deletes very fast. As discussed later in Section 6.1, this may not be the best approach for our XML database.
Detailed System Design
Packages
Figure 2 depicts the six packages that make up the xSQL system.
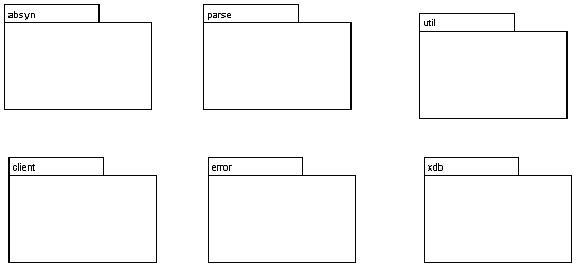
Figure 2. The xsql packages.
The system is composed of the following six Java packages:
1. absyn - this package contains the abstract syntax classes that represent SQL statements as Java classes.
2. parse - this package contains one custom and several generated classes that parse the SQL and create the abstract syntax classes in the absyn package.
3. util - this package contains utility classes for string processing, parsing and normalizing XML.
4. client - this package currently contains only one class called CommandLine which implements the interactive command line interface.
5. error - this package contains a single class used by the parser. Reused this class from a parser created in CISC 630.
6. xdb - this package contains the classes that implement the XML DataBase (thus xdb).
Of these six packages, only two play a major role in the system’s design (absyn and xdb). The others contain only a few supporting classes except client which contains the CommandLine class discussed in section 5.5.
Parse classes
The parse contains one custom class (Parser) and several classes generated by JLex and Java CUP. The requirements for using the JLex lexical analyzer for Java are to create a text specification that describes the tokens to be recognized via regular expressions. Listing 4 conveys a portion of the JLex specification.
Listing 4. JLex Specification
…
NAME=[A-Za-z][A-Za-z0-9_]*
WHITE_SPACE_CHAR=[\f \t\b\012]
EOL = [\r\n]
…
%%
";" { return tok(sym.SEMI, null); }
"," { return tok(sym.COMMA, null); }
…
"WHERE" { return tok(sym.WHERE, null); }
"where" { return tok(sym.WHERE, null); }
"INSERT" { return tok(sym.INSERT, null); }
"insert" { return tok(sym.INSERT, null); }
…
\'{QSTRING}\' { return tok(sym.STRING,
yytext().substring(1, yytext().length() - 1)) ; }
{EOL} { return tok(sym.EOF, null); }
. { err("Lexer: Unknown input"); }
In order to use the Java CUP parser generator, you create a grammar specification for your language that specifies definitions built from terminal and non-terminal symbols. Listing 5 provides a portion of the grammar for SQL.
Listing 5. Abbreviated CUP grammar
// JavaCup specification for a subset of the SQL Grammar
…
parser code {:
Lexer lexer;
SqlStatement stmt;
public SqlStatement getSqlStatement()
{ return stmt; }
…
public Grm(Lexer l, xsql.error.ErrorMsg err)
{
this();
errorMsg=err;
lexer=l;
}
:};
scan with {: return lexer.nextToken(); :};
terminal java_cup.runtime.Symbol INSERT, VALUES,
COMMA, PERIOD, LPAREN,
RPAREN, INTO, SELECT, FROM, SEMI, CHARACTER,
NUMERIC, CREATE, TABLE, INTEGER, DROP, WHERE,
AND, SET, UPDATE, DELETE, ASTERISK, PRIMARY_KEY;
terminal String NAME, INT_NUM, STRING, COMPARISON;
/* */
non terminal insert_statement, select_statement,
sql_statement, sql_batch, create_table_statement,
drop_table_statement, where_clause,
search_expr, search_condition, set_expr,
update_statement, set_clause,
column_commalist, column, values_clause,
value, value_commalist, table, table_commalist,
column_def, column_def_commalist, delete_statement;
/* Grammar */
…
sql_statement ::= select_statement
|
insert_statement
|
create_table_statement
|
drop_table_statement
|
update_statement
|
delete_statement
;
…
select_statement ::= SELECT column_commalist:s1
{:
parser.stmt =
new Select((ColumnNameList)s1);
:}
FROM table_commalist:s2
{:
((Select)parser.stmt).setTableNameList((TableNameList)s2);
:}
where_clause:s3
{:
((Select)parser.stmt).setWhereClause((WhereClause)s3);
:}
;
It is important to notice that the code action taken (demarcated by the ‘{:’ and ‘:}’ markers) creates the Java objects of the abstract syntax (via the Java ‘new’ keyword).
The JLex and JavaCup programs use Listing 1 and Listing 2 specifications (respectively) to generate a parser. That parser is called Grm (short for Grammar) and invoked by the CommandLine class in the xsql.client package and passed the SQL statement. A subclass of the SqlStatement class (discussed in the next section on the absyn package) is returned.
Absyn Classes
The classes in this package are instantiated by the generated parser (created from the CUP grammar as shown in Listing 5). Figure 3 displays the UML class diagram for this package.
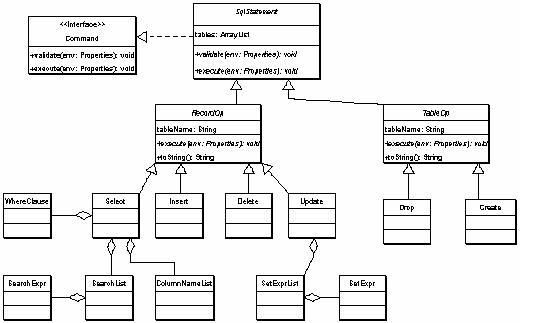
Figure 3. absyn package class diagram.
This package has five key categories of classes/interfaces:
1. Command interface. An interface for an abstract command that contains two methods: validate() and execute(). This is the key abstraction of the Command pattern.
2. SqlStatement abstract class. This class is the root of all Sql statement classes. This is the parent class that the CommandLine class expects from the parser.
3. Record Operations (RecordOp) and Table operations (Table Op). Sql statements are separated into two broad categories - those that operate on whole tables and those that operate on records inside tables.
4. Statement subclasses (Select, Insert, Drop…). Each SQL statement specified in the grammar is implemented with a concrete class. These classes contain helper classes representing parts of the statement (like value lists, and where clauses).
5. Helper classes (WhereClause, expression and name lists). Each type of list is encapsulated in its own class. Additionally any separate clauses like where and set are encapsulated in a class.
Xdb Classes
The classes in this package represent a relation as a set of two RandomAccessFile(s). RandomAccessFile is a java class allowing seeking, reading and writing from any byte position in a file.
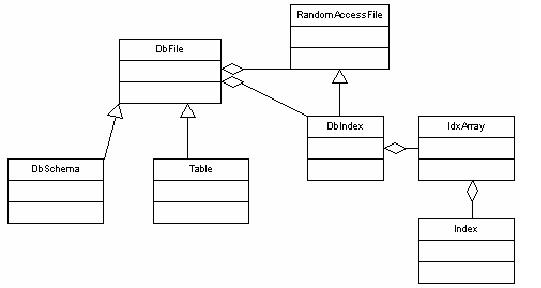
Figure 4. xdb package class diagram.
This package contains three categories of classes:
1. DbFile. This class represents a relational table as a combination of two files (an XML text file and one or more binary indexes).
2. DbFile subclasses (DbSchema, Table). These subclasses of DbFile are required because of their unique XML syntaxes. 1 subclass is required per XML format.
3. DbIndex (and the IdxArray). The DbIndex file is a serialization of an array of Index classes. An index class holds two long values (file position and length) and a short (status). The status is used for the deletion marker.
Collaboration
The main program follows a simple interactive loop and a simple collaboration sequence between three instantiated objects. Figure 5 portrays the object collaboration with the interactive CommandLine class:
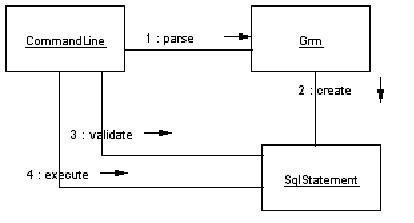
Figure 5. CommandLine collaboration diagram.
The sequences of messages in the collaboration is as follows:
1. Receive Sql String from user.
2. Call the parse method of the parser (called Grm).
3. The parser generates an SqlStatement subclass (which implements the Command interface) as shown in Figure 3.
4. The CommandLine class invokes the validate and execute message on the Command object.
Conclusion
The design was successful and met the goals for XML retrieval, reuse for implementing new user interfaces and robust SQL parsing. This software system provides a good basis for further experimentation along hybrid XML/relational lines.
Implementation Lessons Learned
The implementation of this course project provided valuable experience and three key outcomes:
1. Unfortunately, I was unable to complete 4 out of 14 requirements. I simply ran out of time and certain features took longer than expected. Strove to implement all the basic features first. Successfully implemented 10 out of the 14 requirements. The following requirements were not implemented:
a. 3.1.2.3 Modify Tables.
b. 3.1.4.4 Query with Union.
c. 3.1.4.5 Query with Except.
d. 3.1.4.6 Query with Cartesian Product.
2. Limited or no performance advantage for retrieving XML results from native XML storage due to comparison requirements. In implementing all the variants of select for text results first and then for XML results, the fact that the native storage was XML provided only minor advantages in the final output.
a. Small benefit for selecting all columns (*). This was due to the fact that the indexes are row-based and thus the entire rows was presented without modification. The projections eliminate this advantage to the parsing requirement for specific columns.
3. The chief benefit of the XML backing store is the database representation as XML outside of the database management system.
a. Allows direct manipulation by XML processors.
b. Easy transformation via XSLT.
c. Ability to text index relation data for combined structured and unstructured searches.
d. Deletes would need to be changed to immediate removal to maintain a correct data representation outside of the database management system.
Overall, this was a great experience and sparked many new ideas for future research.
[1] Daconta, Michael C.; Information As Product: How to deliver the right information to the right person at the right time; © 2007 by Michael C. Daconta; Outskirts Press.