 My Corner of the Web
My Corner of the Web
My nephew Jeremy has just started software development courses through Udacity, so I wanted to share with him some of the "best" technology books I have read over the course of more than 30 years in the profession. Which brought me to a fundamental question:
"What do we mean by the BEST"?
The way that I answer these questions is to create a logical model of the context of the question and its component parts (this type of logical model is called "an ontology" which is a fancy word for a specialized type of data model). To do this I use a piece of software that I created called EZKB for Easy Knowledge Bases (it is not feature complete, still in the alpha stage but available to try here) as depicted below. Note: the model below is not complete, it is just a mere start to the model ... as I enhance it I will continue to post the results (and the final product).
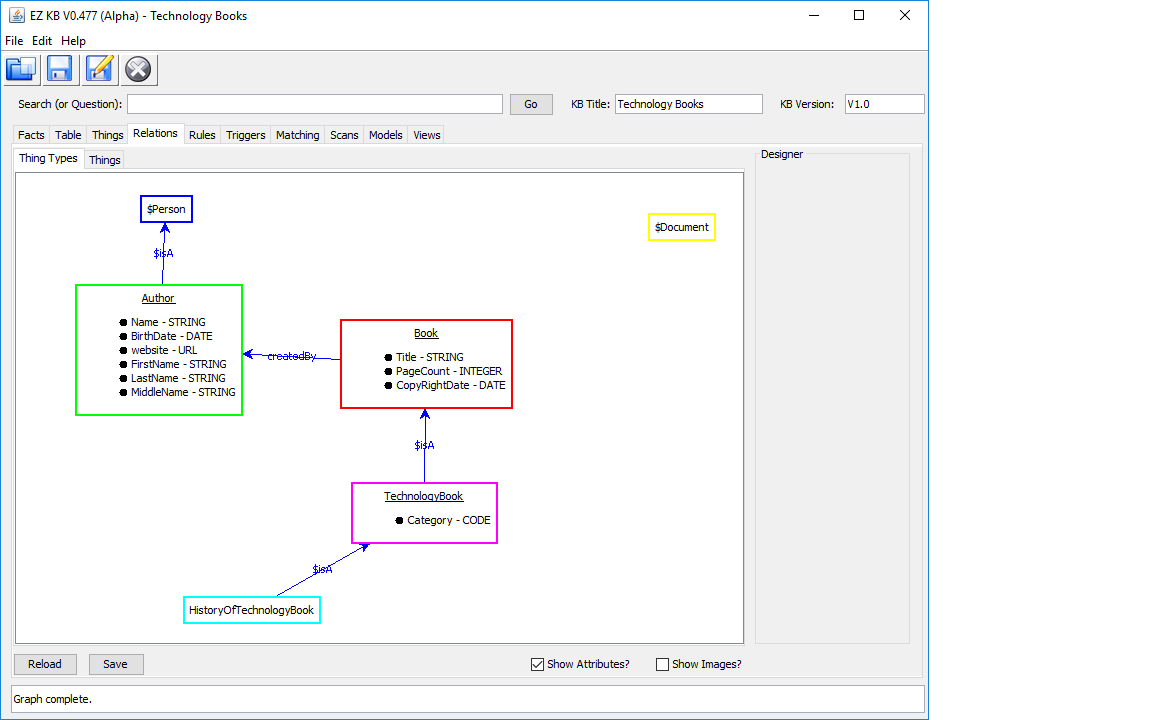
So, how does building a model help me to answer the question of "What are the Best Technology Books?" The answer is that building a knowledge model forces you to think precisely and to tease out the ambiguity from the question. You begin by pealing apart the question at its root - What is a Book? What is an Author? What is a Technology Book? How is a Technology Book different from all other books? What are the relationship between the concepts. For a specific example look at the class at the way bottom of the diagram - "HistoryOfTechnologyBook" ... there are many books that discuss the history of Technology like Steve Jobs (which is also an Autobiograph, possibly another subclass), Fire in the Valley and Hackers (the book by Stephen Levy not to be confused with the movie of the same name). Should we model a class of thing we call "HistoryOfTechnologyBooks as a specialization of TechnologyBooks or do we just include that as a category value (or type of) technology book? In general, the answer depends on whether that class is distinct enough from everything else (with its own unique set of attributes) that is important to the differentiate technology history books from every other type of technology books. Write now I am experimenting by making the HistoryOfTechnologyBooks a subclass of Technology Book (denoted by the special relationship called "isA" which denotes that "HistoryOfTechnologyBook is a Technology Book". Or more formally, a subclass which is a transitive relationship between two classes. A subclass means that all the attributes of the parent class are inherited by its subclass.
As you can also see in the diagram, classes can have attributes, for example, an author has a first name and last name or just a name which can be generated via the concatenation of those two items. Where as subclasses help us tease out the notion of specific versus general things, crafting our attributes correctly help us to elaborate the concept by specifying characteristics that can define its uniqueness. For example, a book has a title,copyright date and is created by an Author. The copyright date lets us place it in a historical context. That is a very important point to capture because the historical context influenced the Author that created the book.
So, up until know all we have received from our modeling exercise is a bit more specificity in understanding the things inside of our domain, we have not yet cracked the question of "How do we determine whether one technology book is 'better than' another technology book?" That is precisely the point in modeling the things in our domain because that question can now be transformed into a simple equation like:
So, the answer to determine what is best is to transform that ambiguous question into one or more specific equations comparing the things represented in our knowledge model and then to test out are rules by mapping and generating instances from other data sources (like mining wikipedia for all technology books).
So, where do we go from here? I will continue to flesh out this model and share with you key decision points along the way. This will include delving into even more complicated modeling techniques like rules. In the end, we will develop rules that execute against our knowledge model to determine what we mean (in this domain) by A is "better than" B. EZKB lets you experiment with different types of rules and how you trigger them ... but that will have to be left for when this knowledge model is a bit more sophisticated. So, stay tuned and I will post updates to this project as I make more progress.